
Written by Sitong An, Artem Golovatiuk, Nathan Simpson, and Hevjin Yarar. Edited by Sitong An.
Foreword
A small squad of INSIGHTS ESRs (Sitong An@ CERN, Artem Golovatiuk @ Università di Napoli, Nathan Simpson @ University of Lund, and Hevjin Yarar @ INFN Padova) visited DESY for the 1st Terascale School of Machine Learning from 22 to 26 October 2018. This is our long overdue account of the school and the competition event that followed (spoiler alert: we won!).
P.S. Nathan, our newly-anointed team vlogger, has made a wonderful video about the event. Check it out at [here]!
A bird’s-eye view of DESY and the Machine Learning School

DESY (Deutsches Elektronen-Synchrotron) is a national centre for Particle Physics, Accelerator Physics and Photon Science in the suburb of Hamburg, Germany. It used to host important Particle Physics facilities like HERA, which was a lepton-proton collider aimed to probe internal structure of protons and properties of quarks (“is there anything smaller hidden inside the quarks?”). Nowadays, the focus of on-site facilities has gradually shifted towards Photon and Accelerator Science, with sizeable groups of researchers working on data from ATLAS and CMS at CERN. DESY is one of the research partners of INSIGHTS, with Dr. Olaf Behnke from DESY as a member of the network.

The 1st Terascale School of Machine Learning covered an introduction to Deep Learning and hands-on tutorials on the usual tools of the trade: PyTorch, Tensorflow and Keras. It also went beyond the basics to include several talks from experts in the fields on advanced topics like GANs (Generative Adversarial Networks) and semi-supervised/unsupervised learning.
Highlight of the Expert Talks
When using machine learning methods in high energy physics (HEP), the usual paradigm is to train on simulated data, while validation and testing are done on real data collected by the detector. In reality, we are unable to perfectly model real data, so there will always be discrepancies between our simulation and the real world. One of the talks was given by Benjamin Nachman on ‘Machine Learning with Less or no Simulation Dependence’, who is tackling this problem with weakly supervised machine learning. Directly training on data is not possible since we do not have labels. However, in the case of two classes (such as q and g for quark vs gluon jets in data) that are well-defined, i.e. q in one mixed sample is statistically identical to q in other mixed samples, two methods were discussed: training using class proportions of mixed samples (ref ) and training directly on data using mixed samples (ref ). This talk was a great opportunity for us to learn about new, simulation-independent approaches in to search for new physics with Machine Learning.
On the last day of the school Gilles Louppe gave a talk on ‘Likelihood-free Inference’. When discriminating between a null hypothesis and an alternative, the likelihood ratio is the most powerful test statistic. In the likelihood-free setup, the ratio of approximate likelihoods is used, which is constructed by projecting the observables to a 1D summary statistics and running the simulations for different parameters of interest. Reducing the problem to 1D is not ideal since we then lose the correlations of the variables. One of the introduced ideas to address this was to do a supervised classification to estimate the likelihood ratio. In this way, one does not need to evaluate individual likelihoods and can use the estimated ratio for inference. For details, here is a link to check out.
The Machine Learning Challenge
As part of the school, a machine learning challenge was held to allow students to test out their newly-acquired skills with a problem and a data set from particle physics. Specifically, this involved the tagging of heavy resonances, i.e. being able to distinguish heavy objects like the top quark, W and Z boson, or the Higgs from light quark and gluon jets. These jets leave energy deposits in the calorimeters in the detector, which can then be mapped to images, which look a bit like this:
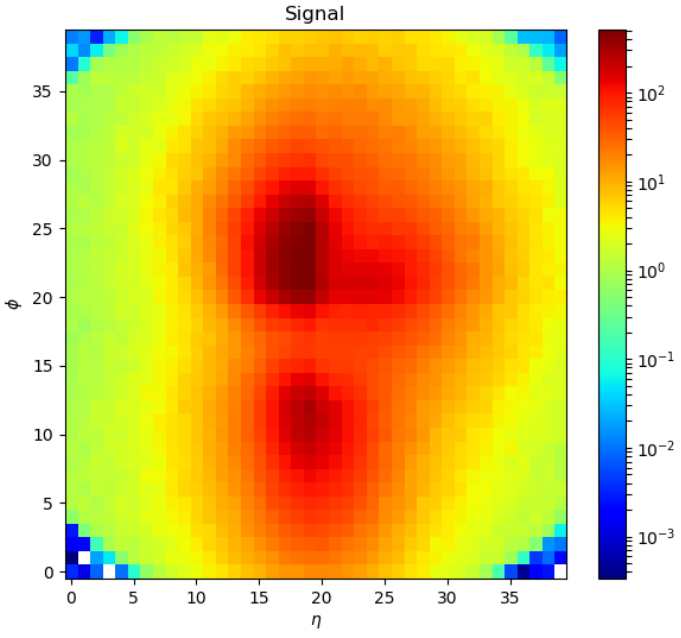
Using these images and the data from the detector, such as transverse momentum, pseudorapidity, and combinations of different variables, we were tasked with building a machine learning solution to classify jets as coming from a top quark or not. The challenge was organised by Gregor Kasieczka, who recently authored a nice summary paper on this very topic (machine learning for top tagging) – check it out at https://arxiv.org/pdf/1902.09914.pdf.
So what did we come up with, and how well did it perform?
Our INSIGHTS team had several major advantages comparing to the other participants. First of all, we were the team of 4 people working together, leading to many fruitful discussions. This also allowed us to try different approaches at the same time and to distribute parts of the task (data preprocessing, trying out different hyperparameters or architecture or the model, etc). What’s more, we had access to the GPU-machine in the University of Naples, which gave us a great boost in computational power and a possibility to play around with relatively large models.
The winning model was jokingly named as “A bit Tricky Beast”, because it was an epic Frankenstein’s monster composed of two Neural Networks trained separately, brought together by the third Neural Network. And there was a little trick in a way we trained the model. First network was a CNN (Convolutional Neural Network) taking jet images as an input. It was already pretty big with about 1.7 million parameters. The second network was an RNN (Recurrent Neural Network) taking the preprocessed constituents. We used particles 4-momenta together with physically motivated high-level features as invariant mass m2, transverse momentum pTand pseudo-rapidity . Finally, as a cherry on the top, we used several fully-connected layers to combine the outputs from CNN and RNN, and produce one number – probability of jet coming from the top quark.
The trick was in the way of handling the data. In order to mimic the effect of data-monte carlo disagreement, the data for scoring the solutions differed from the training data with some small fluctuations. However, the part of test data provided to us and the part organisers used for final scoring had the same fluctuations. Therefore, after a thorough training of our network on the provided training set, we trained it for a bit on the provided test data. This allowed our network to learn some features of the fluctuations applied to the test data and slightly boosted the performance.
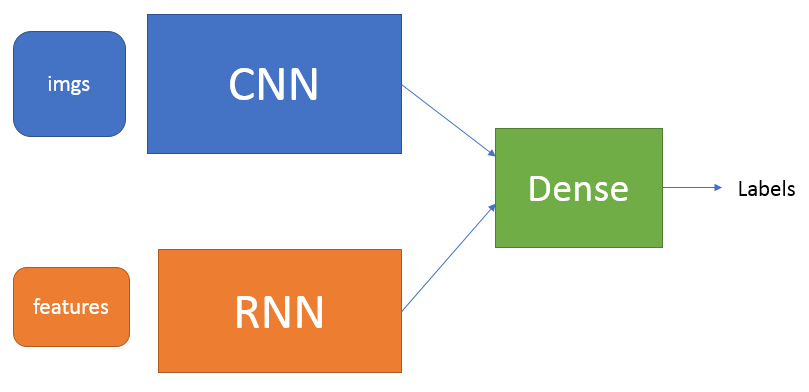
The network itself together with Jupyter notebook can be found at https://github.com/altairjericho/DESY_Terascale
After 9 hours of continuous coding, collaborating and drinking coffee, we produced several networks (with very slight differences among them) that took 6 first best scores on the challenge!

Conclusion
Overall this school was a wonderful and fruitful experience for us. The breadth of the introduction allowed us to learn about and compare different Deep Learning tools, and the talks on the advanced topics offered a glimpse into the kind of problems on the frontier of the field that the experts are working on. And – fairly obviously – we enjoyed thoroughly the hospitality of the school organisers, the tranquil campus of DESY and the city of Hamburg!

